作为一名python爬虫入门兼足球关注者,前段时间看到知乎文章用Python模拟2018世界杯夺冠之路,顿时心痒,也想照着作者的思路去爬取一些关于足球比赛的数据信息,顺便练练手。无奈文章中作者主要讨论数据分析部分,没有给出从球探网爬取数据的代码。我只好自己分析网页,编写爬虫代码,并将爬下的数据存进了csv文件。在这过程中发现遇到了很多以前没有遇到的问题,也get到了一些新技能,故写篇文章总结一下并分享给大家。
这里以爬取球探网上关于2018年俄罗斯世界杯32支参赛国家队的以往6年的比赛数据为例。

一、根据网页内容构建爬取思路
首先在球探网世界杯主题页(2018赛季世界杯(世界杯),赛程积分--球探网)列出了入围分组赛的32支国家队分组和积分情况(当然现在还没有积分数据),点击任意参赛国家队(比如埃及)的名称,可以连接到该国家队专题页(埃及,埃及,Egypt -- 球探网),其中包含了此队从2011年至今所有的比赛成绩和相关数据(这就是我们要爬取的内容。)
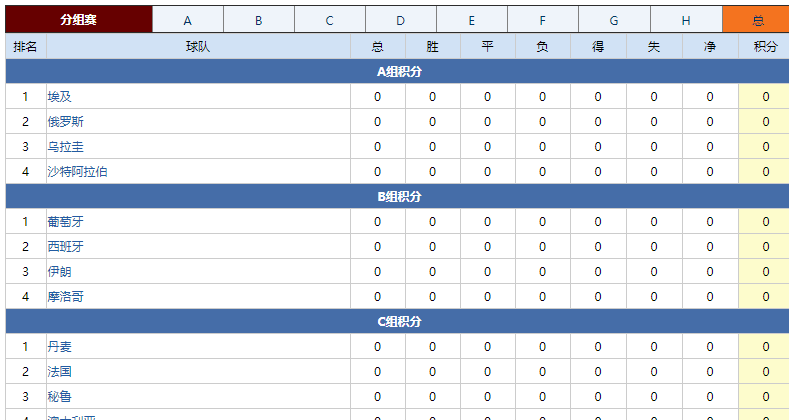
世界杯32强名称及分组信息
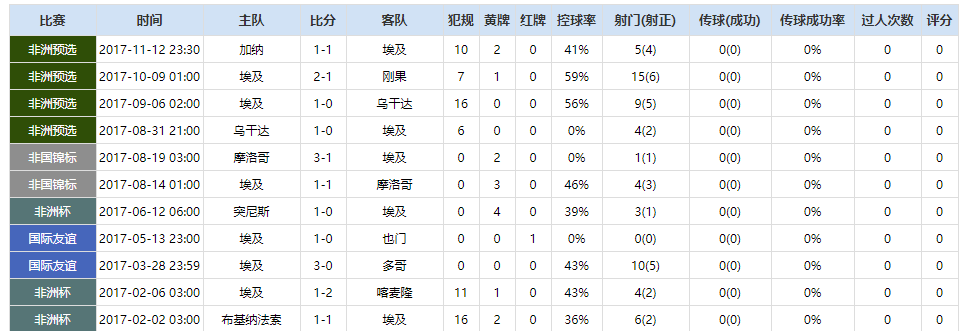
埃及国家队比赛数据统计
所以整个爬取思路拟定为:从2018赛季世界杯(世界杯),赛程积分--球探网抓取参赛国家队名称及其对应的国家队数据统计链接,并以这些链接作为二级网址,抓取对应国家队近年来的比赛数据统计信息。最后将爬取下来的信息存入到一个csv文件中。
二、网页html分析
首先在开发者工具中找到我们要在一级网址上抓取的信息位置。我们要爬取的就是位于<table id="ScoreGroupTab"><tbody>中第三个<tr>标签里的<a>标签内容及href属性。
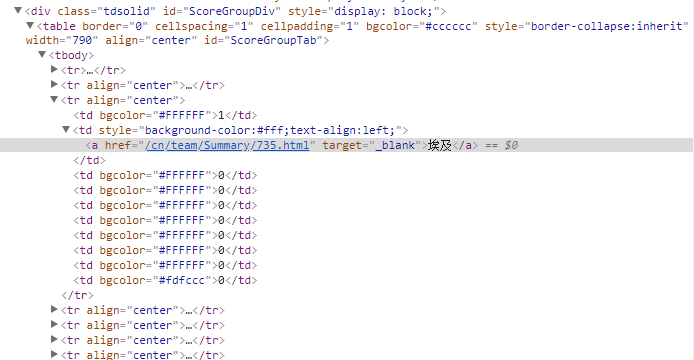
但是在页面点击右键查看源代码时,源代码中并没有上述部分的代码。

说明这部分table标签里的内容是通过ajax动态加载的,不是写在源代码里。开发者工具也显示网页使用了jquery框架编写javascript脚本。(国家队比赛数据统计所在表格也是ajax动态加载的,这里我就不重复分析了。)
在看看请求网页时服务器返回的文件,其中Bomhelper.js中写有如下信息:
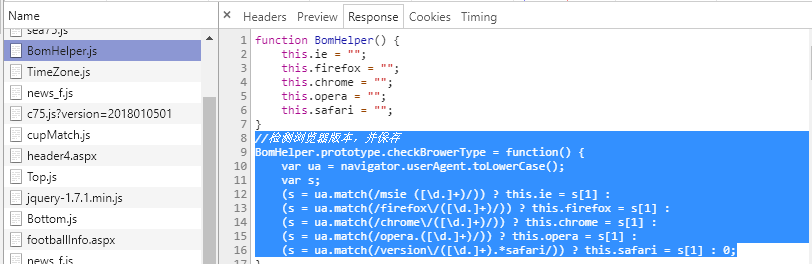
网页设置了浏览器版本检查,只响应ie, firefox, chrome, opera, safari这5中浏览器发送的请求。所以我们在爬虫中就需要使用selenium库来模拟浏览器发送请求了。又由于限制了浏览器版本,所以最常用的无头浏览器plantomJS也不能用了,故这里我们选中chrome浏览器。
三、配置selenium和chrome
既然确定了使用selenium库+chrome浏览器的方法,那么我们首先要安装selenium库和相应的浏览器驱动(chromedriver.exe)
selenium库安装
这个很简单,和常用的python包安装一样,可以使用:
pip install selenium
2. 下载和安装chromedriver
打开https://sites.google.com/a/chromium.org/chromedriver/downloads,下载与浏览器版本相匹配的chromedriver.exe。例如:我的浏览器是 Chrome/60.0.3112.101,而2.33版的chromedriver刚好支持。所以就选用2.33版的。

下载的是一个zip文件,解压后,里面有一个chromedriver.exe文件,将该文件移动到电脑chrome浏览器的安装目录下,我的是:C:\Program Files、(x86)\Google\Chrome\Application,并把该路径添加到环境变量的path中。
3. 验证chromedriver是否可用
打开python,输入一下内容:
from selenium import webdriverdriver = webdriver.Chrome()
点击运行后,此时如果一个chrome浏览器窗口被成功打开,并且程序没有报错,则说明配置成功了。如果浏览器在打开后不久程序报错:[WinError 10054] 远程主机强迫关闭了一个现有的连接。则有可能是chromedriver.exe的版本低了,换个更新的版本应该就没事了。
四、爬虫代码
铺垫了这么多,终于来到主要内容了。不多说了,先上代码,细节请看注释。
#导入需要的包from selenium import webdriverimport timeimport traceback#发送url请求def getDriver(url):
try:
# 注意chromedriver的版本
driver = webdriver.Chrome()
driver.get(url)
time.sleep(1)
return driver
except:
return ''#获取子链接列表def getURLlist(url, teamURLlist):
driver = getDriver(url)
try:
#找到包含子链接的所有a标签
a_list = driver.find_elements_by_xpath('//table[@id="ScoreGroupTab"]/tbody/tr/td[2]/a')
if a_list:
for i in a_list:
#teamURLlist用于存放子链接
teamURLlist.append(i.get_attribute('href'))
driver.close()
return teamURLlist
else:
return []
except:
traceback.print_exc()
return []#获取比赛数据def getMatchInfo(teamURLlist, fpath):
with open (fpath, 'w') as f:
#注意逗号后面不要有空格
f.write('比赛,时间,主队,比分,客队,犯规,黄牌,红牌,控球率,射门(射正),传球(成功),传球成功率,过人次数,评分\n')
if teamURLlist:
for url in teamURLlist:
driver = getDriver(url)
# 表格中数据数据分了好多页,虽然所有数据在driver.page_source中都可见。
# 但是,除第一页以外,其他的数据style属性都是“display:none",selenium对这些元素是无法直接操作的。
# 我们需要通过JavaScipt 修改display的值
# 编写一段javascript代码,让浏览器执行。从而把html中的所有tr标签的style属性都设为display='block'
js = 'document.querySelectorAll("tr").forEach(function(tr){tr.style.display="block";})'
driver.execute_script(js)
#接下来,就可以把所有的比赛成绩数据都爬下来
infolist = driver.find_elements_by_xpath('//div[@id="Tech_schedule"]/table/tbody/tr')
# 第一个tr中包含的是表格的title信息,剔除
for tr in infolist[1:]:
td_list = tr.find_elements_by_tag_name('td')
matchinfo = []
for td in td_list:
# 部分td的style属性也为“display:none",info 则对应为‘’,
# 这些td对应的是角球,越位,头球,救球,铲球等信息,不是很重要,就不爬取了。
info = td.text
if info: # 去除空字符
matchinfo.append(td.text)
matchinfo.append(',') #添加逗号作为分隔符
matchinfo.append('\n') #在列表最后加上换行符
#将一条比赛信息写入到文件中
f.writelines(matchinfo)
#每个网页爬完后,就把打开的浏览器关掉,要不最后会开着好多浏览器窗口。
driver.close()def main():
#一级网址:32强分组信息
start_url = 'http://zq.win007.com/cn/CupMatch/75.html'
#保存文件及路径
output = r'D:/03-CS/web scraping cases/qiutan/worldcup2018.csv'
startlist = []
resultlist = getURLlist(start_url, startlist)
getMatchInfo(resultlist, output)
print('\nfinished\n')main()值得提一下,爬取中涉及到获取属性为display:none的标签内容,这需要编写一段javascript代码来修改属性值,并交个浏览器来执行。
最后的爬取结果如下:
五、小结
这个过程主要用到如下知识点:
使用selenium+chrome的组合来模拟chome浏览器发送请求,处理ajax异步加载数据以及服务器对发送请求浏览器的限制。
解决了如何爬取属性为display: none的标签内容:编写一段修改属性的javascript代码交个webdriver去执行。
将爬取到的数据写入csv文件
有一个缺点就是整个爬取过程有点慢,打开浏览器加载数据这一消耗了很多时间,未来要想办法改进一下!
足球预测软件下载: